|
| Home > Che cos'è il social software? Architettura delle reti e politiche del nuovo discorso scientifico |
Sappiamo dunque che è possibile navigare soltanto in una frazione del Web, vale a dire che la maggior parte delle sue pagine può essere rintracciata soltanto conoscendone l'indirizzo (URL) e che solo una minima parte di esse è raggiungibile a partire da altri nodi della ragnatela. Ma come giungiamo a un sito che ci interessa? Lo strumento essenziale a reperire le informazioni contenute nelle pagine Web sono i motori di ricerca. Digitando una o più parole su google, il sito di google ci restituisce un elenco di link a pagine che contengono informazioni pertinenti ai fini della nostra ricerca. Tuttavia, non sempre le informazioni che troviamo corrispondono a quanto cerchiamo; viceversa, di solito la parte maggiore dei risultati è decisamente “fuori tema”. Infatti, se i motori di ricerca si sono dimostrati utilissimi nel setacciare rapidamente un numero molto elevato di pagine, non si rivelano altrettanto utili nel valutare la qualità del documento. Assieme a informazioni rilevanti, i motori ci restituiscono moltissimi link a pagine il cui contenuto è estraneo a quanto cerchiamo. Un problema che non dipende dalle caratteristiche topologiche della rete, ma da un suo limite architettonico.
In pratica, le difficoltà che incontrano i motori di ricerca dipendono dal fatto che questi si limitano a controllare la presenza nei documenti di determinati termini (parole chiave), un indizio che dice molto poco sul reale contenuto delle pagine che troviamo 63 . Perché dunque non si investe nel migliorare le tecniche e gli algoritmi di ricerca? In parte, lo si fa. Tuttavia, l'architettura originaria del Web presenta alcuni limiti che non dipendono da un difetto negli algoritmi di ricerca utilizzati dai motori. Il limite principale consiste piuttosto nel fatto che, sul Web, le diverse informazioni di un documento HTML sono mescolate al suo interno e non sono strutturate semanticamente, rendendo impossibile alle macchine trattare i dati sparsi nelle pagine secondo il significato che attribuiamo loro nel contesto in cui sono inseriti - mentre il significato dei dati all'interno del contesto è essenziale in qualsiasi ricerca.
Prendiamo ad esempio il caso in cui io decida di vendere la mia automobile tramite un annuncio in rete. L'annuncio che decido di postare in una pagina Web è più o meno del tipo “Vendo Toyota Yaris nera, ottimo stato, buon prezzo, Pisa, Italia”. Tuttavia, se cerco “Yaris nera in vendita a Pisa, Italia”, i motori di ricerca mi restituiranno un elenco sterminato di pagine che contengono quelle parole, ma il cui contenuto, nella maggior parte dei casi, sarà molto lontano da quello che desidero, informazioni che vengono definite noise, “chiasso”, poiché distolgono la mia attenzione dai risultati che effettivamente mi interessano. Otterrò invece risultati migliori decidendo di inserire la mia offerta in un sito specializzato che contiene un modulo i cui campi di ricerca siano predefiniti e indichino, ad esempio, la casa automobilistica, il modello, l'anno di immatricolazione dell'auto e altri dati rilevanti ai fini della ricerca. Questo perché la pagina è scritta in un formato leggibile da una macchina, la quale sarà in grado di conservare il significato delle singole parti del documento.
Nel processo di ricerca non conta soltanto trovare la risposta a una domanda; ad assumere un rilievo fondamentale sono le strutture in cui è inserita la singola informazione. Il progetto originario del Web prevedeva in effetti che tali strutture fossero in qualche modo visibili e rintracciabili tanto dagli umani quanto dai computer 64 . Viceversa, sul Web come è stato implementato e come lo conosciamo, i link non sono “etichettati”. Questa caratteristica ne indebolisce le potenzialità.
Dal 1999 il World Wide Web Consortium (W3C), il consorzio fondato e diretto da Tim Berners-Lee allo scopo di promuovere standard che assicurino l'interoperabilità del Web, ha concentrato le ricerche sui modi in cui risolvere il problema, dando vita a un orientamento noto come Web semantico 65 . Scopo di tale orientamento è progettare e sviluppare una estensione del Web che lo trasformi in una ragnatela di dati elaborabili dalle macchine. La scommessa fatta propria dal W3C è far diventare la rete in grado di interpretare le nostre richieste. Il web diviene semantico nel momento in cui, nella rete di collegamenti tra dati di natura differente ed espressi in forma diversa, i computer diventano in grado di trattare i dati in modo da inferire nuova conoscenza a partire da quella nota. Da un punto di vista tecnico, ciò è possibile strutturando l'informazione in modo tale che i documenti non restino “isole di dati” ma diventino “data base aperti” da cui un programma possa attingere informazioni.
Per comprendere il senso di tale affermazione, è utile introdurre la differenza tra “information retrieval” (recupero di informazione) e “data retrieval” (vale a dire: risposta automatizzata alle domande). Obiettivo della prima è produrre documenti che sono rilevanti per una query; questi documenti non devono essere unici, e da interrogazioni successive possono dare luogo a risultati completamente diversi. Obiettivo del secondo è invece produrre la risposta corretta a una domanda. Il Web semantico si occupa di questo aspetto 66 . Ma che cosa significa Web semantico, in pratica? E come ci apparirà il nuovo Web? Una prima risposta si trova nell'esempio che segue:
Quando il telefono squillò, il sistema di intrattenimento stava cantando a squarciagola “We Can Work It Out” dei Beatles. Nel momento in cui Pete alzò la cornetta, il suo telefono abbassò il volume mandando un messaggio a tutti i dispositivi locali con un controllo del volume. All'altro capo della linea c'era sua sorella, Lucy, dallo studio medico: "la mamma ha bisogno di una visita specialistica e poi dovrà eseguire una serie di trattamenti. Due volte a settimana, o giù di lì. Ora chiedo al mio agente di fissare gli appuntamenti". Pete accettò subito di condividere l'impegno.
Dallo studio del medico, Lucy istruì il suo agente semantico attraverso il browser del suo palmare. L'agente di Lucy trovò immediatamente dall'agente del medico le informazioni relative al trattamento prescritto, controllò diverse liste di offerte e controllò quelle che rientravano nel piano assicurativo della madre nel raggio di 20 miglia da casa sua, e con un rating di fiducia eccellente o molto buono. Poi l'agente cominciò a provare a cercare gli appuntamenti liberi (offerti dagli agenti dei singoli provider tramite i loro siti Web) compatibili con le disponibilità di Lucy e di Pete (le parole in corsivo indicano i termini la cui semantica, o significato, vengono definiti per gli agenti attraverso il Web semantico).
In pochi minuti, l'agente presentò loro un programma. Pete non lo ritenne adeguato. Lo University Hospital si trovava dalla parte opposta della città rispetto alla casa della madre, e avrebbe dovuto tornare indietro nel caos del traffico dell'ora di punta. Programmò il suo agente in modo da rifare la ricerca con preferenza più strette su luogo e orario. L'agente di Lucy, avendo completa fiducia in quello di Pete riguardo a questa specifica ricerca, fornì a quello assistenza immediata fornendogli l'accesso ai certificati e agli shortcut dei dati che aveva trovato.
Quasi istantaneamente fu presentato un nuovo programma: la clinica era molto più vicina e gli orari precedenti, ma c'erano due avvertimenti. In primo luogo, Pete avrebbe dovuto spostare due appuntamenti poco importanti. Controllò di che cosa si trattava, e vide che non era un problema. L'altro riguardava il fatto che la clinica non rientrava nell'elenco di terapeuti coperti dalla compagnia di assicurazione: l'agente lo rassicurò “Servizio coperto e piano assicurativo verificato sicuro da altri mezzi” “(Dettagli?)”
Lucy si mise assente nello stesso istante in cui Pete brontolava: “risparmiami i dettagli” e tutto fu risolto 67 .
Abbiamo osservato come, da un punto di vista tecnico, l'architettura originale del Web si basasse esclusivamente su tre princìpi semplici: URL (la possibilità di puntare a una risorsa dandole un nome dal significato univoco), HTTP (il protocollo di trasporto delle pagine sul Web) e HTML (il linguaggio di codifica delle pagine Web, che permette di inserire link). Per far sì che i computer possano essere in grado di eseguire compiti come quello descritto, si sono rese necessarie alcune trasformazioni nell'architettura del Web. Che cosa significa strutturare semanticamente l'informazione? E come si può farlo?
È possibile costruire una risposta a entrambe le domande considerando da vicino le trasformazioni tecnologiche sulle quali si fonda il Web semantico, oggi detto anche Web dei dati. Da un punto di vista architettonico, il Web semantico è stato rappresentato nel 2001 da Tim Berners-Lee come una piramide di sette strati e composta da nove elementi, una piramide in cui gli strati sono collegati tra loro attraverso tre tipologie di informazioni («documenti auto-descrittivi», «dati» e «regole»).
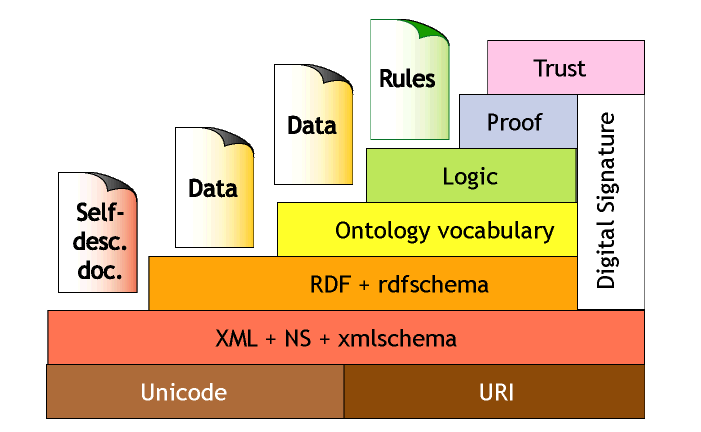
Il significato della nuova architettura dev'essere spiegato a partire dalla base della piramide. Gli elementi in basso sorreggono gli strati più alti, e ne sono una precondizione. Infatti, il rapporto tra un piano della piramide e quello successivo può essere interpretato come un rapporto di condizionamento inteso in senso kantiano, vale a dire che il web può essere concepito come un insieme di strati con standard, linguaggi o protocolli che agiscono come piattaforme sulle quali possono poggiarsi formalismi nuovi, più ricchi e più espressivi. Piattaforme che sono intese più neutrali possibile, in cui l'architettura a strati ha funzione di regolamentazione e non è prescrittiva 68 . Un'analogia che può aiutare a comprendere il tipo di rapporto che esiste tra i sette strati della «torta semantica» è quella con il funzionamento di un aeroporto, dove la partenza e l'arrivo di ogni aereo dipendono dalla corretta concatenazione ed esecuzione di una serie di procedure standard (dal check-in dei passeggeri al loro sbarco, dalla spedizione alla riconsegna dei bagagli, dalle fasi di decollo e di atterraggio, seguite dai piloti e monitorate dalle torri di controllo, etc...).
E' inoltre importante osservare che, nel passaggio dagli strati inferiori a quelli superiori (in particolare gli ultimi due, «Proof» e «Trust»), le innovazioni che sono introdotte sono poco definite sul piano tecnologico. Ciò che viene invece illustrato è piuttosto l'impatto socio-culturale che le trasformazioni in atto nell'architettura del Web saranno in grado di produrre nelle comunità che operano sul Web, un aspetto di particolare interesse ai fini del nostro discorso.
Un'analisi dettagliata dell'architettura del Web semantico esula dallo scopo di questo contributo. Qui ci limitiamo a riassumere gli aspetti essenziali delle innovazioni tecnologiche proposte, che possiamo concentrare in quattro punti:
a ) Metadati («dati sui dati»): servono a descrivere o annotare una risorsa in modo da renderla maggiormente comprensibile agli utenti. Normalmente i metadati sono di natura descrittiva e includono informazioni relative a un documento tra cui l'autore, il titolo o l'abstract, il tipo di file, i diritti d'accesso o il numero di versione. L'aggiunta di dati sui dati è utile per organizzare le risorse, per l'archiviazione e per identificare l'informazione. Tuttavia, la funzione più importante dei metadati è promuovere l'interoperabilità, consentendo la combinazione di risorse eterogenee tra diverse piattaforme senza perdere informazioni rilevanti 69 .
Si parla infatti di «open data» per definire un'importante caratteristica del web semantico, cioè la disponibilità dei dati e la conseguente possibilità di identificarli e citarli. Il Web semantico è perciò un'estensione del Web tradizionale nel senso che è il successivo passaggio nel linking e pensato per funzionare nel contesto di un modello relazionale di dati, in cui il link, da collegamento generico e cieco tra due documenti, diviene capace di esprimere relazioni concettuali, che convogliano significati. In pratica, sul web ogni “dato”, pezzetto di informazione, viene identificato da un URI. Perciò, si usa dire che sul web semantico, tutto è un URI.
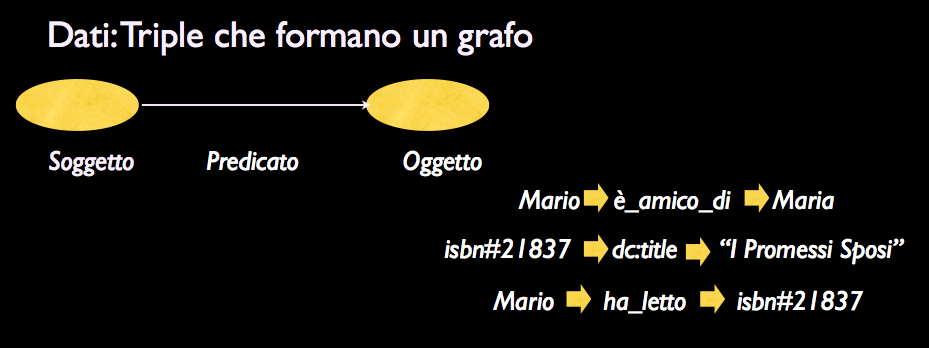
b) Gli URI (identificatori di dati) vengono messi in relazione tra loro tramite il linguaggio Resource Description Framework (RDF), che consente di costruire asserzioni tramite triple formate da soggetto predicato e oggetto e di collegare tra loro le triple in un unico grafo (in cui soggetto e oggetto sono nodi, URI, e il predicato è il link). Si vedano le figura sotto, per un esempio. La prima mostra come si costruiscono le triple.
La seconda mostra come si costruiscono grafi con RDF:
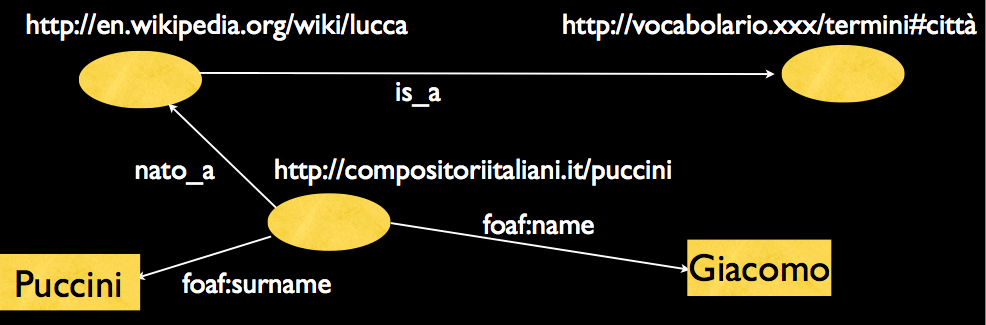
c) Per esplicitare in modo formale un determinato campo di conoscenze, è necessario un ulteriore passaggio che permetta di associare i concetti a regole logiche d'uso. Questo compito è assegnato alle ontologie. In filosofia, un'ontologia è una teoria sulla natura dell'essere di tipi di oggetti; in senso più tecnico, è un accordo che si basa su definizioni condivise e che rappresenta la base concettuale su cui operiamo. Il termine è diventato di uso comune tra i ricercatori che si occupano di intelligenza artificiale e del Web, e in questo significato l'ontologia è un documento che definisce in modo formale le relazioni tra termini 70 . Nel grafo della figura sopra è già presente un'ontologia. Si tratta del link “is_a” tra “lucca” e “città”. “is_a” è in effetti una relazione che fa parte dei mattoni costituenti per creare un'ontologia. Relazioni come “is_a” sono in un certo senso predefinite: sono gli assiomi del linguaggio, i connettori logici. La tipica ontologia per il Web ha una tassonomia e un insieme di regole di inferenza. La tassonomia definisce classi di oggetti e le relazioni tra essi. Così, il significato dei termini in una pagina web può essere stabilito da puntatori che linkano a un'ontologia. Un agente semantico che cerchi l'ospedale di Pisa e trovi “Santa Chiara” deve poter capire che non cerchiamo una biografia di Santa Chiara, né una chiesa o una Chiara qualunque. L'ontologia è un albero che permette di esprimere restrizioni sui termini (condizioni), quindi relazioni. Attraverso le relazioni della logica descrittiva si può esprimere in maniera formale qualsiasi oggetto o concetto. Le ontologie dunque contengono le specifiche dei concetti necessari a comprendere un dominio di conoscenza, il vocabolario corrispondente, e il modo in cui concetti e vocabolari sono collegati e in cui sono definite e descritte le classi, le istanze e le loro proprietà 71 .
Un'ontologia può essere formale o informale. Il vantaggio di un'ontologia formalizzata risiede nel fatto che questa è machine-readable, vale a dire che un computer può compiere dei ragionamenti a partire da essa. Di contro, lo svantaggio sta nella difficoltà di implementare tali costrutti formali.
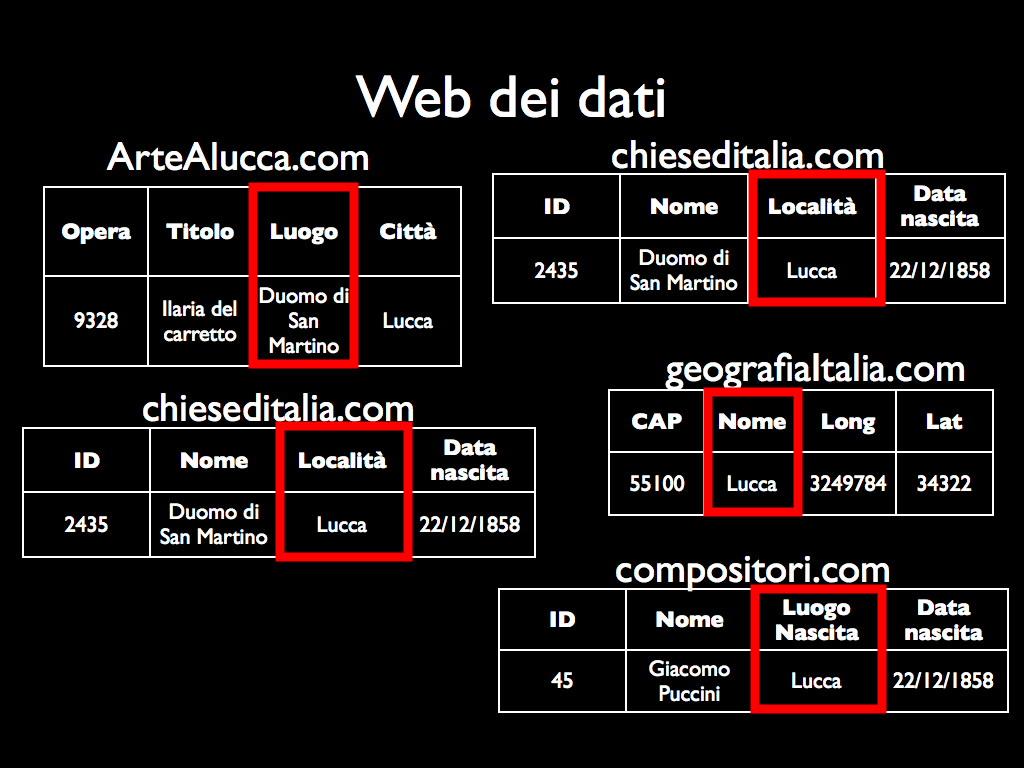
È intuitivo osservare che due basi di dati possono usare identificatori differenti per il medesimo concetto. Un programma che voglia confrontare o combinare informazioni nei due database deve sapere che più termini possono riferirsi al medesimo oggetto. Idealmente, il programma deve essere in grado di riconoscere due termini come sinonimi. La soluzione a questo problema è data dalle altre ontologie 72 – le quali debbono mettere in correlazione i dati usando una lingua franca in modo da facilitarne la condivisione. Si veda nella figura sotto un esempio.
Sul piano dell'implementazione, l'ontologia esistente più diffusa è Wordnet 73 , che descrive i concetti (sinonimi, contrari, relazioni tra concetti) in diverse lingue. La peculiarità di tale sistema è che è in grado di effettuare ricerche di “dipendenza concettuale”, come ad esempio le relazioni meronimiche (parte-tutto), sineddotiche o metonimiche (per esempio, se cerco un ospedale nella città di Lucca, è essenziale che il sistema sappia in qualche modo che Lucca è in Toscana e che la Toscana si trova in Italia).
Si osservi che chiunque può creare una propria ontologia di riferimento (sperando che venga condivisa) o adottarne una esistente, optando così per una altrui prospettiva. In genere, le ontologie sono create all'interno di comunità di conoscenza. Un problema, riscontrato e segnalato in particolare da filosofi e sociologi, è che ciascuno definisce il mondo a suo piacimento, e che proprio la creazione di queste definizioni è parte integrante del mestiere del ricercatore in scienze umane e sociali. Dunque, esiste un alto rischio di creare sistemi che si sovrappongono o che sono in conflitto, mentre la ricerca di un'unica ontologia, se da una parte sarebbe auspicabile, può comportare il pericolo insito nella rigidità delle interpretazioni di fatti e fenomeni.
Tuttavia, tale limite o pericolo può diventare una ricchezza. E' infatti auspicabile che vengano create molte e diverse ontologie, poiché più sistemi di classificazione sono in grado di stabilire una corrispondenza tra nomi e oggetti meglio di un unico vocabolario; inoltre, è possibile creare meta-ontologie che stabiliscano corrispondenze tra sinonimi, e che mettano a loro volta in relazioni vocabolari distinti. Ontologie diverse possono essere intersecate in modo da stabilire analogie, vale a dire relazioni di equivalenza. Spesso, gruppi diversi elaborano indipendentemente concetti molto simili e descrivere la relazione che esiste tra questi porta grandi benefici. Per un software, potrà essere dunque normale avere a che fare con ontologie differenti e magari in parte conflittuali nello stesso dominio di conoscenza, e sarà un compito del programma stesso mostrarne le diversità, aiutando così a migliorare la comprensione del concetto in questione.
Un'altra garanzia di pluralità, per la quale i teorici del web semantico si distinguono dalle teorie dell'intelligenza artificiale, è data dalle implicazioni della cosiddetta Open World Assumption, secondo la quale il valore di verità di un'asserzione è indipendente dalle conoscenze dell'osservatore. In altre parole, questo significa che se un osservatore non sa se un'asserzione è vera non può inferire che essa sia falsa (come invece accadrebbe invece in un mondo in cui vale la Closed World Assumption).
L'unione dei dati espressi in RDF e dei dati espressi in un linguaggio delle ontologie (ad esempio OWL) permette di inferire nuova conoscenza. È questo lo strato della logica, in cui trova spazio il «reasoning», l'inferenza di nuova conoscenza: per costruire procedure analoghe al ragionamento software appositi devono essere in grado di collegare i termini, una funzione che sarà resa possibile tramite i linguaggi di inferenza. I linguaggi di inferenza consentono alle macchine di convertire dati da un formato all'altro, riconoscendo due termini come identici e traducendoli, un po' come fa un dizionario bilingue. Si tratta di una funzione fondamentale poiché nessuno ha il potere di definire un termine per tutti; questi linguaggi si occupano pertanto di identificare relazioni tra basi di dati per stabilire la presenza di sinonimi. Per tornare all'esempio di Lucy e Pete alla ricerca di un medico per il trattamento prescritto alla madre, grazie ai linguaggi di inferenza potrà essere trovato l'ospedale giusto anche cercando “clinica” o “hospital”, e via dicendo. Questa specifica funzione è assegnata a motori di ricerca logici, motori in grado di applicare le regole della logica per stabilire se le risposte ottenute in una ricerca iniziale sono utili o no. Nell'esempio, è un motore che riesca a rintracciare le informazioni relative alla loro specifica richiesta e a combinare i criteri da loro definiti: il trattamento richiesto e la copertura assicurativa dell'assistita, la distanza dalle rispettive abitazioni, gli orari in cui si sono resi disponibili, e altre informazioni rilevanti.
d) Infine, un concetto essenziale è quello di fiducia (Trust).
La rete di fiducia è un modello essenziale del modo in cui lavoriamo realmente come persone. ognuno di noi costruisce la sua rete sin dall'infanzia. Man mano che decidiamo cosa linkare, cosa leggere o comprare sul web, un elemento che entra a far parte della nostra decisione è quanto possiamo fidarci dell'informazione che vediamo. Potremo fidarci del nome del suo editore, delle pratiche di tutela della privacy, delle motivazioni politiche? Certe volte impariamo nel modo peggiore che non dobbiamo fidarci, ma più spesso ereditiamo la fiducia da altri, da un amico o da un insegnante o da un familiare, o da raccomandazioni edite oppure da garanzie di terzi come la banca o il dottore. 74
La costruzione di reti di fiducia è necessaria a implementare sistemi di filtro dell'informazione secondo criteri di qualità condivisi ma soggettivi, ed è uno dei temi su cui discute da anni il W3C 75 . In particolare, sul Web il concetto di fiducia assume notevole importanza da un punto di vista socio-culturale, sul piano cioè della trasformazione dei comportamenti dei navigatori della rete. Perciò, le implicazioni di questo concetto saranno approfondite nell'ultimo paragrafo.
La rete semantica è dunque in grado di descrivere l'informazione, poi di dedurre nuova conoscenza e infine di ragionare a partire da essa. E' questo, in sintesi, il sistema necessario a far funzionare i nostri agenti semantici nella storia di Lucy e Pete.
Quando migliaia di moduli saranno collegati in tutto il campo “cognomi”, allora tutti quelli che analizzeranno il Web capiranno che è un importante concetto comune. La cosa bella è che nessuno dovrà compiere realmente questa analisi. Il concetto di “cognome” comincerà semplicemente a emergere come caratteristica importante di una persona. Come un bambino che impara un'idea tramite contatti ripetuti, la Rete Semantica “impara” un concetto tramite contributi ripetuti da diverse fonti indipendenti. […] Il ragionamento che sta dietro questo approccio, quindi, è che non esiste un magazzino centrale dell'informazione, e nessuna autorità su alcunché. Collegando le cose tra di loro potremo fare molta strada verso la creazione di una comprensione comune. La Rete Semantica funzionerà quando ci saremo messi d'accordo sui termini, ma anche se non ci saremo riusciti. 76
La pretesa della rete semantica non è dunque quella di poter rappresentare tutti i dati o il sapere in qualche ristretto insieme di formalismi, ma piuttosto fare sì che la possibilità di linkare i dati a nuovi dati permetta di usarli in modo sempre più ampio. L'ambizione del W3C consiste nell'incrementare i dati a disposizione, e nel valorizzarli tramite nuove tecnologie che si aggiungono ai pilastri del Web. L'estensione del livello di inferenza che può essere ottenuta automaticamente non è dunque uno scopo ma semmai una conseguenza auspicabile 77 .
Questa evoluzione facilita la creazione di gruppi con interessi comuni, vere e proprie comunità aperte in rete. Nonostante le applicazioni del Web Semantico siano per il momento confinate per lo più all'ambito accademico, le loro possibili implicazioni cominciano a diventare evidenti. Restando nei confini della ricerca accademica, non è difficile vedere le implicazioni di tale rivoluzione non solo nella scienza del Web, ma anche nella pratica della ricerca dell'informazione in generale. Grazie alla costruzione di un Web ipertestuale, un gruppo di qualsiasi dimensione può comunicare con facilità, acquisire sapere e veicolarlo velocemente, superare le incomprensioni e ridurre la ridondanza degli sforzi. «L'universalità, scrive ancora Tim Berners-Lee, deve esistere in molte dimensioni. Tanto per cominciare, dobbiamo essere in grado di collegare tra loro molti documenti, dalle bozze alle successive versioni fino ai documenti finiti» 78 . Un passaggio essenziale a non perdere i passaggi del processo di un ragionamento, perché quando facciamo ricerca il processo tramite cui si raggiunge un risultato è importante al pari del risultato stesso. «Qualora nuove persone entrassero in un gruppo, avrebbero a disposizione tutto un passato di decisioni e motivazioni. Quando lasceranno il gruppo, il loro lavoro sarebbe già stato assorbito e integrato. E come interessante bonus, l'analisi automatica della rete di conoscenza potrebbe consentire ai partecipanti di trarre conclusioni sulla gestione e l'organizzazione della loro attività collettiva, un'impresa che non sarebbe stata possibile altrimenti» 79 . Uno scenario che non è molto distante da quello prefigurato, nel 1945, da Vannevar Bush.
[63] T. Berners-Lee, L'architettura del nuovo Web, cit., p. 155.
[64] Si osservi con attenzione la figura 1 nella prima proposta presentata da Berners-Lee al CERN ( Information Management: A proposal, marzo 1989-maggio 1990). Nella figura, gli archi che collegano le singole pagine (e che corrispondono ai link) sono contrassegnati da “etichette” che definiscono il tipo di collegamento che esiste tra due risorse. I tipi di collegamento possono essere diversi: ad esempio “Tim Berners-Lee” “ha scritto” “questo documento”. “Questo documento” “descrive” “l'ipertesto”. Le relazioni “ha scritto” e “descrive” si traducono banalmente in link. Ma sono link dal significato diverso; un significato che, nell'idea originaria di Web, veniva esplicitato.
[65] Si veda in particolare questa sezione del sito del W3C: <http://www.w3.org/2001/sw/>.
[66] T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit., p. 18.
[67] T. Berners-Lee, J. Hendler, O. Lassila, «The Semantic Web. A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities», Scientific American Magazine, 17 maggio 2001, online all'URL: <http://www.sciam.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21>.
[68] Gli studiosi di Web science sostengono che il rapporto tra gli strati si possa definire come supervenienza, termine che in filosofia indica un modo per spiegare la generazione di significati per cui un discorso A è superveniente a un discorso B se un cambiamento in A comporta un cambiamento in B, ma non viceversa. T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit., p. 72.
[69] Schemi di metadati sono ad esempio quelli Dublin Core, un sistema costituito da un nucleo di elementi essenziali ai fini della descrizione di qualsiasi materiale digitale accessibile tramite la rete. Per l'uso di chi naviga sul Web, i metadati possono essere non-strutturati; viceversa, per essere comprensibili alle macchine è necessario che tali informazioni siano strutturate. RDF offre meccanismi per integrare schemi di metadati. Cfr. T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit, pp. 36-39.
[70] Nel campo delle «computational ontologies», si parla di ontologie con due accezioni diverse, entrambe corrette. La prima accezione intende con ontologia l'insieme sia dei dati, sia dei vocabolari; nella seconda accezione, l'ontologia è l'insieme dei soli vocabolari. In logica descrittiva si fa distinzione tra Abox e Tbox come due componenti distinti delle ontologie. La Tbox definisce un vocabolario e le relazioni tra gli elementi del vocabolario, la Abox è un insieme di asserzioni compatibili con quanto definito dalla Tbox. Qui intendiamo l'ontologia nella seconda accezione.
[71] T. Gruber, «A translation approach to formal ontologies», Knowledge Acquisition, vol. 5, no. 25, pp. 199–200, <http://ksl-web.stanford.edu/KSLAbstracts/KSL-92-71.html>, 1993.
[72] Le ontologie sono scritte in RDF Schema, OWL (Onthology Web Language), e in altri linguaggi appositi. Come ad esempio DAML, DAMOIL.
[73] Cfr. paragrafo 8.
[74] T. Berners-Lee, L'architettura del nuovo Web, cit., pp. 137-38.
[75] Ivi, pp. 134-37.
[76] Ivi, p. 163.
[77] Ivi, p. 30.
[78] Ivi, p. 128.
[79] Ivi, p. 143.
 This work is licensed under a Creative Commons License |
