|
| Home > Che cos'è il social software? Architettura delle reti e politiche del nuovo discorso scientifico |
La disponibilità di una grande quantità di dati è una precondizione allo sviluppo del Web 2.0, espressione coniata dall'editore americano Tim O'Reilly per definire «un insieme di tendenze economiche, sociali e tecnologiche che formano collettivamente la base per la futura generazione di Internet, che diventa un mezzo più maturo» e definito sulla base di alcune caratteristiche: partecipazione degli utenti, apertura ed effetti di rete 99 .
L’aspetto tecnologico del Web 2.0 è funzionale alle caratteristiche delle reti sociali e della cooperazione tra utenti, e le tecnologie che vengono sviluppate poggiano sui princìpi architettonici di Internet, Web e web semantico, vale a dire l'apertura e l'universalità che si esplicano nell'architettura a strati, nella decentralizzazione, nella «open world assumption», nella centralità degli URI e nel principio del «data linking».
Si afferma un principio noto come « mash up » (letteralmente: “poltiglia”) 100 , che consiste nella combinazione e nel riutilizzo di informazioni e servizi. Un esempio di ciò è la combinazione di un servizio google come google maps con altri servizi, ad esempio flickr, il sito che consente agli utenti di pubblicare sul web le proprie fotografie; nello specifico, la combinazione di google maps con flickr permette di localizzare e visualizzare le fotografie su una mappa. La tecnologia che permette di farlo sono le API (Application programming interface), insiemi di procedure, strutture dati, classi di oggetti e protocolli forniti dalle librerie e dai servizi del sistema operativo per supportare l'implementazione di applicazioni, che, quando liberamente disponibili, si dicono aperte (Open API).
I princìpi della programmazione di software libero/open source includono il fatto che gli utenti siano coinvolti nel processo di programmazione e trattati come co-sviluppatori, che il software sia reso pubblico spesso e non subordinato all'accumularsi di miglioramenti e innovazioni sostanziali, e un modello di progettazione indipendente dall'hardware (ora sempre più aperto anche ai cellulari) e a strati.
Il web fa dunque da specchio alla società umana di cui riflette gli interessi, che si estendono su un arco molto ampio di assunti, valori e culture. La rete è così usata per condividere informazioni, per divertirsi, per fare scienza in modi radicalmente nuovi, per il business 101 . Il Web 2.0 è stato così rappresentato «come un insieme di princìpi e di procedure che collegano un autentico sistema solare di siti che fanno propri tali prìncipi, in tutto o in parte, a una distanza variabile da tale centro.» 102 Quali sono dunque i princìpi che caratterizzano la fisionomia del web 2.0? I concetti, o architravi portanti della sua struttura tecnica e sociale, sono sintetizzabili in cinque punti:
1) "Il web come piattaforma".
I servizi web sostituiscono sempre più le applicazioni desktop. Un esempio è l'account di Google, che offre gratuitamente agli utenti collegati l'integrazione di servizi prima disponibili solo in locale, come ad esempio editor di scrittura (tipo word) e suite di applicazioni come Microsoft Office. Google diviene così l'intermediario tra utenti e informazione, in cui le applicazioni non sono concepite come pacchetti in vendita ma fornite come servizio, senza licenze o condizioni di vendita, e senza richiedere il porting su piattaforme diverse affinché i clienti possano utilizzare il software sulle proprie macchine (in termini tecnici: platform independent). Un corollario di questa trasformazione è che il software è concepito sempre più come un servizio e non come un prodotto. Il modello google si contrappone così al modello tradizionale à la Microsoft: «da una parte, un singolo fornitore di software, la cui massiccia base e il sistema operativo strettamente integrato con le API permettono di controllare il paradigma di programmazione; dall’altra, un sistema senza un proprietario, tenuto insieme da una serie di protocolli, standard aperti e accordi di cooperazione.» 103
Con il Web 2.0 si supera il concetto di sito web come entità autonoma incapace di comunicare con il mondo esterno; si diffondono molte applicazioni sviluppate dal basso da comunità decentralizzate, che rientrano nel cosiddetto social software; inoltre, i dati online diventano indipendenti dalle applicazioni e possono essere utilizzati da servizi diversi.
2) Centralità dei dati e contenuti prodotti dagli utenti.
«Senza i dati, scrive ancora O'Reilly parafrasando una nota affermazione di Kant, gli strumenti sono inutili; senza il software, i dati sono ingestibili». Google si configura così come un insieme di strumenti software e un ampio database specializzato 104 . La disponibilità di un'enorme quantità di dati è una caratteristica fondamentale del nuovo web.
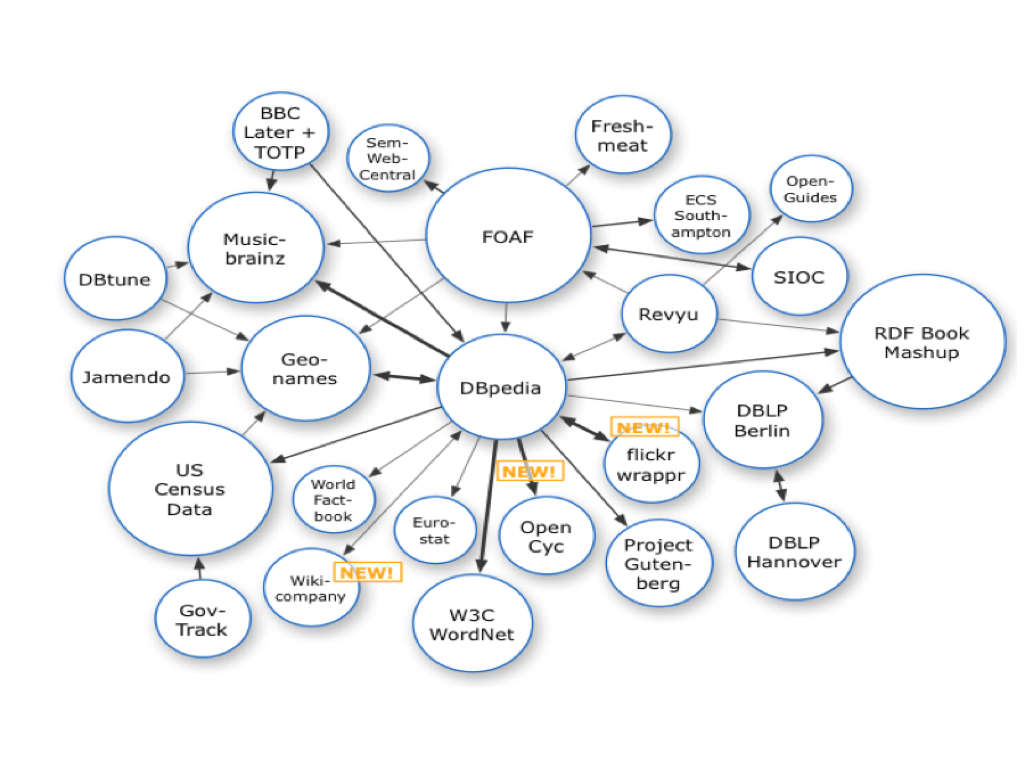
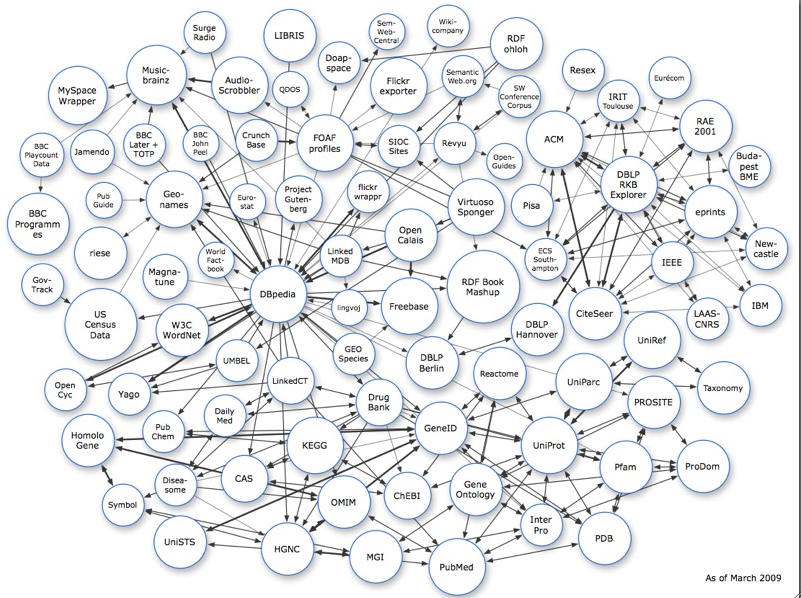
I contenuti sono generati dagli utenti e condivisi all’interno di comunità. In questo modo, sono gli stessi utenti a creare il “servizio” 105 . È questo un elemento caratterizzante il web 2.0 e il social software: «Da “The computer moves in” a “Yes, you. You control the information age. Welcome to your world”. Dall’ormai celebre copertina del Time del 3 gennaio 1983 106 , che nominava il personal computer come “machine of the year”, a quella, quasi un quarto di secolo dopo, del 25 dicembre 2006 107 , in cui il titolo di “man of the year” va alla seconda persona, sia singolare sia plurale, della lingua inglese, scritta, o meglio, digitata al centro di un monitor». L'uomo dell'anno, recita il Time, sei tu. Benvenuto nel tuo mondo. «Se nel gennaio del 1983 la figura umana veniva presentata stilizzata e glaciale di fronte al computer, sul cui schermo comparivano numeri e grafici, in un ambiente cupo dove, per contrasto, solo la sedia ed il tavolo erano caratterizzati da un aspetto tradizionale e da colori caldi 108 , nella copertina del 2006 questa presenza è totalmente astratta, ridotta all’essenza di un pronome personale, al posto dei grafici nel monitor, ora a cristalli liquidi.» 109 La rete di calcolatori lascia così spazio alle reti sociali sul web, in cui gli utenti producono e condividono contenuti, arricchendoli di ulteriori dati e collegandoli tra loro. I blog sono, in questo contesto, un importante strumento di pubblicazione interamente nelle mani degli utenti che si diffondono anche grazie ai “trackback”, link monodirezionali che creano l’effetto di collegamenti a due vie, i quali incrementano il grado di connessione dei contenuti e creano zone in cui il Web si presenta come una rete indiretta e più facile da navigare. «La “blogosfera” può essere considerata un nuovo equivalente peer-to-peer di Usenet e dei bulletin-board, le aree conversazionali del primo internet. Non solo è possibile iscriversi ai siti degli altri e collegarsi facilmente ai singoli commenti su una pagina: tramite un meccanismo noto come trackback si può anche vedere quando qualcun altro si collega alle proprie pagine e rispondere, con link reciproci o aggiungendo commenti».
Si diffondono infine “folksonomie”, termine che deriva dalla contrazione dei termini “folks” e “taxonomy” e che consistono in stili di categorizzazione collaborativa che utilizzano parole chiave liberamente scelte, generalmente definite tag. Se l'uso di ontologie aggiunge una struttura ai dati, in questo secondo caso la struttura emerge in modo organico dall'organizzazione delle richieste informative dei singoli individui. Le ontologie vengono integrate da folksonomie, che sorgono quando un ampio numero di persone è interessato a qualche informazione e incoraggiato a descriverla – in gergo, a taggarla.
All'aumentare dei tag inseriti dagli utenti, questi tendono a essere riusati e applicati a nuovi elementi da altri utenti. Certamente, la libertà nell'assegnare parole chiave a un contenuto può creare un eccesso di informazione e una certa confusione. Tuttavia, i tag sono generati dalle interazioni che avvengono nel mondo reale e rilevano connessioni reali tra contenuti e utenti. Tali strutture permettono alla semantica di emergere da accordi impliciti (ex post), diversamente da quanto avviene nella costruzione di ontologie, le quali indicano accordi espliciti (ex ante); il campo delle dinamiche semiotiche ha come premessa l'idea che gli accordi comunicativi o i sistemi di organizzazione dell'informazione spesso si sviluppano attraverso processi decentralizzati di invenzione e negoziazione 110 .
Tuttavia, la distinzione tra ontologie e folksonomie ha un notevole rilievo su un piano filosofico, e merita qualche parola in più. È stato infatti osservato che le folksonomie sono preferibili all'utilizzo di ontologie controllate e centralizzate. Se infatti la possibilità di annotare pagine web usando vocabolari controllati può accrescere le possibilità di trovare ciò che cerchiamo con esattezza, d'altra parte una base ampia ed eterogenea di utenti non consente che siano molte le persone che scelgono di adottare o di mantenere un'ontologia complessa. Creare ontologie richiede un investimento di tempo e di energie molto elevato. Tuttavia è altrettanto vero che le parole chiave scelte da una persona in modo indipendente e scoordinato dagli altri possono essere inutili o inaccurate, e anche se l'uso di folksonomie è assai diffuso, queste rimangono uno strumento di classificazione impreciso. Allo stesso tempo, però, la diffusione di strumenti per l'uso di ontologie è assai più lenta di quanto non stia avvenendo per le applicazioni sociali che si servono delle folksonomie. Dunque, è inopportuno e improprio considerare folksonomie e ontologie come strategie mutuamente escludentisi – molto meglio invece adottarle come complementari. Le prime si rivelano così di grande utilità per la ricerca di documenti da parte degli utenti; le seconde sono essenziali per il recupero automatizzato di dati, in modo particolare in campo scientifico 111 . Gli esempi di convergenza tra l'impostazione del web semantico e quella del web2.0 non mancano. Tra gli altri, vale la pena ricordare Visual Thesaurus 112 , un dizionario della lingua inglese, che utilizza il software di visualizzazione ThinkMap 113 e che è basato su WordNet 114 , un database lessicale della lingua inglese il cui progetto è stato avviato nel 1985, in cui i termini sono organizzati tra di loro sulla base di rapporti semantici che caratterizzano le classificazioni ontologiche (iponimia, ipernimia, olonomia e meronimia). Il vocabolario presenta i vari significati di un termine in forma di grafo i cui rami sono tipizzati in base al tipo di relazione. « Inserendo “Information” ad esempio, si può navigare il grafo fino ad arrivare ai termini “Data” e “Knowledge” da un lato, e “Entropy” dall’altro. E ancora, “Love” presenta numerosi nodi, che coprono tutti i vari significati del termine, dai significati più astratti all’attrazione fisica, e presenta anche, con un rapporto di antinomia, la parola “Death”» 115 . L'uso di WordNet con ThinkMap dimostra come sia possibile creare servizi avanzati sulla base di contenuti organizzati semanticamente.
3) Intelligenza collettiva.
«L’architettura di internet, e il World Wide Web, così come i progetti di software open source come Linux, Apache, e Perl, è tale che gli utenti che perseguono i propri interessi “egoistici” costruiscono un valore collettivo come conseguenza automatica. Ognuno di questi progetti ha un piccolo nucleo centrale, meccanismi di estensione ben definiti e un approccio che consente a chiunque di aggiungere qualsiasi componente ben funzionante, facendo crescere gli strati più esterni di quello che Larry Wall, il creatore di Perl, definisce “la cipolla”. In altre parole, queste tecnologie dimostrano gli effetti della rete, semplicemente attraverso il modo in cui sono state progettate» 116 . Una conseguenza di questo fatto è la nascita di reti sociali tra persone che condividono gli stessi interessi, i cui esempi più noti sono Myspace e, soprattutto, Facebook, il cui numero di utenti ha raggiunto, nell'aprile 2009, i duecento milioni, e il cui successo è dato dalla facilità con cui è possibile trovare e collegarsi ad altri utenti già presenti nel “mondo piccolo” network.
Un altro esempio illustre di intelligenza collettiva è Wikipedia, un’enciclopedia online basata sull’idea che ciascuna voce possa essere aggiunta e modificata da chiunque e che applica alla creazione di contenuti il detto di Eric Raymond (coniato originariamente nel contesto del software open source), secondo cui «con molti occhi puntati addosso, ogni bug diventa una bazzecola» 117 . L'impostazione di Wikipedia si sta diffondendo anche in ambito scientifico e letterario, dove il tradizionale sistema delle recensioni su carta è affiancato da veri e propri servizi on-line come quello di Internet Bookshop, Amazon.com e Anobii, che oltre alle recensioni consente agli utenti di inserire moltissime informazioni (data di inizio e fine lettura, commenti come nelle note a margine, un voto che va da uno a quattro) e che contiene oltre undici milioni di libri. 118 Vale infine la pena ricordare strumenti per la creazione di bibliografie collaborative come Citeulike e Connotea, che permettono di pubblicare sul web liste bibliografiche e di navigare nelle bibliografie altrui tramite folksonomie, e servizi più evoluti per la ricerca scientifica come Zotero , un'estensione del browser firefox che avvicina sempre di più il desktop virtuale del ricercatore alla sua scrivania tradizionale, arricchita da funzioni eccezionali. Un tool particolare, ad esempio, permette di annotare i testi con note a margine, proprio come si fa con i documenti cartacei. Dei vari “online reference managers” forse Zotero è quello che può maggiormente rispondere ai bisogni degli umanisti che lavorano prevalentemente sui testi (fonti primarie e secondarie). Zotero permette di gestire i documenti di archivi online (come ad esempio JSTOR), dei word processor (sia online, tipo Google doc, sia offline) e dei siti commerciali (Amazon, Google scholar) oltre a vere e proprie “note” aggiunte dal lettore.
4) Decentralizzazione: ogni client è anche un server (P2P).
Molti sistemi del web2.0 sono pensati e progettati per incoraggiare la partecipazione diretta degli utenti in almeno tre modi, indicati da Dan Bricklin come segue: «Il primo, dimostrato da Yahoo!, è di pagare le persone perché lo facciano. Il secondo, che prende ispirazione dalla comunità open source, è di cercare volontari che realizzino lo stesso compito. L'Open Directory Project, un concorrente open source di Yahoo, ne è il risultato. Ma Napster ha dimostrato un terzo modo. Avendo come default la possibilità di mettere a disposizione automaticamente qualsiasi pezzo musicale che viene scaricato, Napster ha consentito a ogni utente di contribuire all’aumento del valore del database condiviso. Questo stesso approccio è stato seguito da tutti gli altri servizi di condivisione di file P2P.» 119 I protocolli peer to peer trasformano i client (componenti che accedono ai servizi o alle risorse) in server (componenti che forniscono servizi). In pratica, sezioni particolari della memoria dei calcolatori degli utenti divengono accessibili agli altri utenti.
4) Accesso aperto.
In tale contesto, le licenze software e il controllo delle API divengono irrilevanti in quanto il software non ha più bisogno di essere distribuito ma solo utilizzato, e il suo valore è proporzionale alla scala e al dinamismo dei dati che esso aiuta a gestire. L'accesso aperto permea così tutti gli strati della rete, dai protocolli ai contenuti, ed è un principio che informa la rete ad ogni livello, definendo tanto gli aspetti tecnici tanto la filosofia e gli aspetti socio-culturali del cosiddetto software sociale.
Da tali premesse gli umanisti e gli scienziati sociali dovrebbero partire per prendere finalmente parte alla discussione e alle decisioni, di natura tanto tecnica quanto politica, su almeno due questioni che sono oggi al centro del dibattito della scienza del Web.
La prima riguarda la cosiddetta governance del Web. Se infatti la struttura decentralizzata della rete non facilita l'imposizione di standard, la creazione di un'infrastruttura attenta alle policy dovrà essere affrontata nello sviluppo degli strati più alti del Semantic Web, studiando il modo in cui rendere possibile l'implementazione di regole per diritti d'accesso, misure di sicurezza e rispetto della privacy degli utenti 120 .
La seconda questione, particolarmente rilevante per la ricerca scientifica sul Web, è relativa al problema della qualità delle informazioni accessibili in rete. Come possiamo fare in modo che il Web contenga buona scienza, piuttosto che mere superstizioni? Come trovare l'equilibrio migliore tra il libero scambio di opinioni e la selezione di informazioni secondo criteri di qualità?
Sul Web esistono siti, detti autorità (authority), che contengono molti link in entrata, vale a dire che sono ritenuti affidabili e pertanto ricevono molti link da altre pagine; e siti detti connettori (hub), che hanno un alto numero di link in uscita e che sono ritenuti attendibili in quanto puntano a informazione valida. Il problema della qualità dei contenuti è legato alla loro ricezione da parte dei lettori, una questione che dipende da criteri soggettivi e che rientra nell'ultimo strato del “layer cake” semantico, la “fiducia” (trust). È intuitivo che si tratta di un fattore importante per lo sviluppo del Web da molti punti di vista: i contenuti scientifici sono ritenuti attendibili in quanto contengono risultati validi; l'autore di un sito ha la fiducia dei lettori che lo conoscono; e lo stesso vale per i servizi che hanno dimostrato di essere affidabili (per esempio, per quanto riguarda la gestione dei dati delle carte di credito o dei dati personali). Perciò, la fiducia è un elemento essenziale nell'architettura del Web. E tuttavia, sul piano teorico, è un tema difficile e sfuggente, sia perché l'architettura del Web consente l'anonimato e rende estremamente facile la copia, sia a causa dei molteplici contesti in cui avvengono le interazioni sul Web. È stato osservato che spesso non è facile distinguere tra l'attendibilità e le sue cause 121 ; inoltre, spesso l'affidabilità di un sistema e la fiducia in un individuo sono state assimilate; infine, le definizioni di fiducia differiscono in modo sostanziale, rendendo difficile la costruzione di una teoria adeguata ad affrontare i problemi tecnici che si presentano agli sviluppatori che si propongono di implementare applicazioni per la selezione dell'informazione sulla base di criteri univoci, un problema che si scontra tra l'altro con la difficoltà di fissare una tantum un concetto che è tutt'altro che statico, bensì variabile nel tempo e nello spazio, e che non ha soltanto una valenza privata ma un importante impatto pubblico. Tuttavia, è essenziale considerare con un'impostazione differente il problema dell'affidabilità di un sistema e quello della fiducia in un individuo. Il primo problema riguarda questioni relative alla Web governance come la sicurezza e la privacy cui si è accennato sopra. Il secondo problema è più delicato in quanto chiama in causa la reputazione di un individuo, un elemento essenziale nella costruzione della fiducia e però più soggettivo e difficilmente definibile in termini universali (la buona reputazione di una persona ad esempio non garantisce che questa si comporti in futuro come ha fatto in passato). Lo studio di tecniche adeguate per comprendere come si forma la reputazione richiede dunque di seguire e approfondire più linee di ricerca, che coinvolgano tanto tecnici quanto filosofi e scienziati sociali 122 ; una questione tra le altre, che mostra come i problemi epistemologici e morali siano parte indispensabile nell'agenda della scienza del Web.
[99] Cfr. T. O'Reilly, Che cos'è web 2.0, 2004 online all'URL: <http://www.awaredesign.eu/articles/14-Cos-Web-2-0>. Si veda anche il bellissimo video “Web 2.0 ... The Machine is Us/ing Us” di Michael Wesh docente di antropologia culturale alla Kansas State University, online su Youtube all'URL: <http://www.youtube.com/watch?v=6gmP4nk0EOE>.
[100] In termini informatici, indica un'applicazione che usa contenuto da più sorgenti per creare un servizio completamente nuovo.
[101] T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, p. 80.
[102] T. O'Reilly, «Che cos'è web 2.0», cit.
[103] T. O'Reilly, «Che cos'è web 2.0», cit.
[104] T. O'Reilly, «>Che cos'è web 2.0», cit.
[105] Il web è ricco di esempi. Tra essi, oltre al già citato Flickr vale la pena menzionare Youtube e ebay, che non hanno bisogno di spiegazioni.
[108] Un approccio visuale simile sarà utilizzato l’anno successivo nel famoso spot pubblicitario “1984” di Ridely Scott per l’Apple Macintosh. Il video dello spot è disponibile on-line a diversi indirizzi, per maggiori informazioni vedi <http://en.wikipedia.org/wiki/1984_%28television_commercial%29>.
[109] F. Meschini, «eContent: tradizionale, semantico o 2.0?», online all'URL: <http://dspace.unitus.it/handle/2067/162>.
[110] T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit. p. 32.
[111] Ivi.
[115] F. Meschini, «eContent: tradizionale, semantico o 2.0?», cit.
[116] T. O'Reilly, «Che cos'è web 2.0», cit.
[117] Ivi.
[118] Si veda L. Lipperini, “«La critica fai da te. Dai libri al web, ecco il popolo dei recensori»”, la Repubblica, 2 giugno 2009.
[119] D. Bricklin, The Cornucopia of the Commons, cit in T. O'Reilly, «Che cos'è web 2.0», cit.
[120] D. J. Weitzner, J. Hendler, T. Berners-Lee, and D. Connolly, «Creating a Policy-Aware Web: Discretionary, rule-based access for the World Wide Web», in E. Ferrari B. Thuraisingham (a cura di), Web and Information Security, Hershey PA: Idea Group Inc, 2005 <http://www.mindswap.org/users/hendler/2004/PAW.html; T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit., pp. 99-100.
[121] S. Grabner-Kräuter, E. A. Kaluscha, “Empirical research in on-line trust: A review and critical assessment,” International Journal of Human-Computer Studies, vol. 58, pp. 783–812, 2003.
[122] T. Berners-Lee, W. Hall, J.A. Hendler, K. O’Hara, N. Shadbolt and D.J. Weitzner, A Framework for Web Science, cit., pp. 89-94.
 This work is licensed under a Creative Commons License |
